AnimateZero:
Video Diffusion Models are Zero-Shot Image Animators
Generated Image
Output Video
Generated Image
Output Video
Generated Image
Output Video









Generated Image
Output Video
Generated Image
Output Video
Generated Image
Output Video
Our Unique Insights and Proposed Zero-Shot Methodology
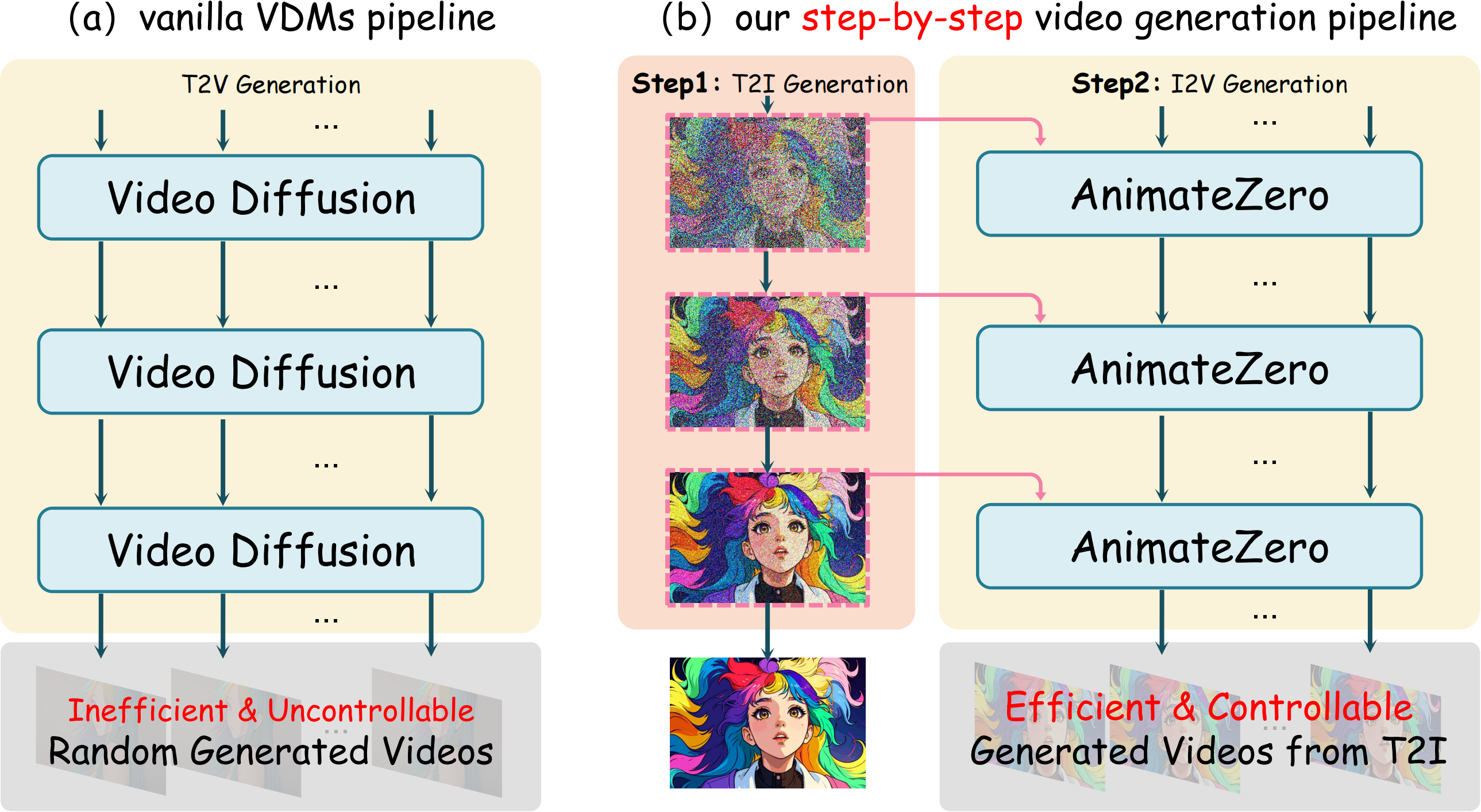
Vanilla Video Diffusion Models (VDMs) have the following issues demonstrated in (a) of the following figure:
We propose step-by-step video generation pipeline to address the above issues demonstrated in (b) of the following figure:
Moreover, we discovered that with just zero-shot modifications, we can transform pre-trained T2V models into I2V models, which means that Video Diffusion Models are Zero-Shot Image Animators!
Gallery
Below, we showcase the videos generated by AnimateZero on a variety of personalized T2I models.



Model: ToonYou




Model: CarDos Anime



Model: Anything V5



Model: Counterfeit V3.0





Model: Realistic Vision V5.1



Model: Photon



Model: helloObject
We also demonstrate an approach to control the motion of generated videos using text. In the following examples, we control the final state of the video by interpolating the text embeddings, thus achieving text-controlled motion.
Generated Image
Output Video
+ "happy and smile"
+ "angry and serious"
+ "open mouth"
+ "very sad"

Application: Video Editing
AnimateZero can also be used for better video editing, both for generated videos and real videos. One common use of AnimateDiff (AD) is to assist ControlNet (CN) in video editing, but it still has a domain gap problem. AnimateZero (AZ) has obvious advantages in this regard, namely generating videos with higher subjective quality and higher matching degree with the given text prompt.
Original Video
CN+AD
CN+AZ (ours)
Original Video
CN+AD
CN+AZ (ours)
"A girl swimming in lava"
"A girl is running in the forest, grassland"
"A candle is burning purple flames by the seaside"
"cute cat, colorful fur"
"A girl is dancing"
"a driving red car"
"A woman with red glasses"
"A young woman"
Application: Frame Interpolation
Extending the technology proposed by AnimateZero can simultaneously insert the first and last frames generated, realizing gradual transitions between the two frames, i.e., frame interpolation.
First Frame
Last Frame
Output Video
First Frame
Last Frame
Output Video












Application: Looped Video Generation
Looped video generation is a special case of frame interpolation, when the first frame and the last frame inserted are the same.
Generated Image
Output Video
Generated Image
Output Video
Generated Image
Output Video






Application: Real Image Animation
AnimateZero has the potential to do real image animation, although the domain gap problem still exists, which is limited by the domain of the T2I model used.
Real Image
Output Video
Real Image
Output Video
Real Image
Output Video



BibTeX
@misc{yu2023animatezero,
title={AnimateZero: Video Diffusion Models are Zero-Shot Image Animators},
author={Yu, Jiwen and Cun, Xiaodong and Qi, Chenyang and Zhang, Yong and Wang, Xintao and Shan, Ying and Zhang, Jian},
booktitle={arXiv preprint arXiv:2312.03793},
year={2023}
}
Project page template is borrowed from AnimateDiff.